In the fast-paced world of software development, ensuring your application is truly ready for production is crucial. A comprehension production readiness checklist serves as your roadmap to a successful deployment. This guide will walk you through the essential components of a production readiness checklist, helping you minimize risks and maximize the reliability of your software in a production environment.
What is Production Readiness?
Production readiness refers to the state in which software is fully prepared to operate in a production environment with minimal risk of failure. It ensures the application is secure, scalable, reliable, and easily observable under real-world conditions. This readiness is critical for delivering a seamless user experience and meeting organizational and compliance requirements.
Key Components of Production Readiness
- Security Measures: Address potential vulnerabilities through code scanning, encryption, and adhering to best practices for secure APIs and authentication. Implement a robust incident response plan for handling and securing breaches.
- Scalability: Test your application’s ability to handle increased traffic and resource demands. Use load testing tools to simulate varying loads and identify bottlenecks. Adopt horizontal and vertical scaling strategies as needed.
- Observability: Ensure your application has monitoring, logging, and tracking capabilities. Tools like Prometheus, Grafana, and Elasticsearch can help track metrics and troubleshoot effectively.
- Reliability: Build resilience in your application with features like auto-recovery, circuit breakers, and health checks. Implement redundant systems and disaster recovery strategies to aim for high availability.
Implementing a robust production readiness process provides several compelling benefits that can significantly enhance the quality and reliability of your application. It helps you:
- Reduce Downtime: Proactively identifying and addressing potential issues before deployment minimizes the risk of unexpected outages. This leads to higher system availability, reduced disruptions, and greater end-user trust.
- Improve User Experience: A production-ready application is optimized for performance and reliability, delivering faster load times, smoother interactions, and fewer errors. These factors contribute to a positive user experience and increased customer satisfaction.
- Reducing Cost: Catching and resolving issues during the development and testing phases is far less expensive than fixing them after deployment. A well-prepared application also reduces operational costs by avoiding unplanned maintenance and emergency fixes.
- Maintain Regulatory Compliance: Many industries enforce strict security, privacy, and reliability standards. Production readiness ensures adherence to these requirements, helping you avoid penalties, maintain regulatory approvals, and safeguard your organization’s reputation.
Why is a Production Readiness Checklist Crucial?
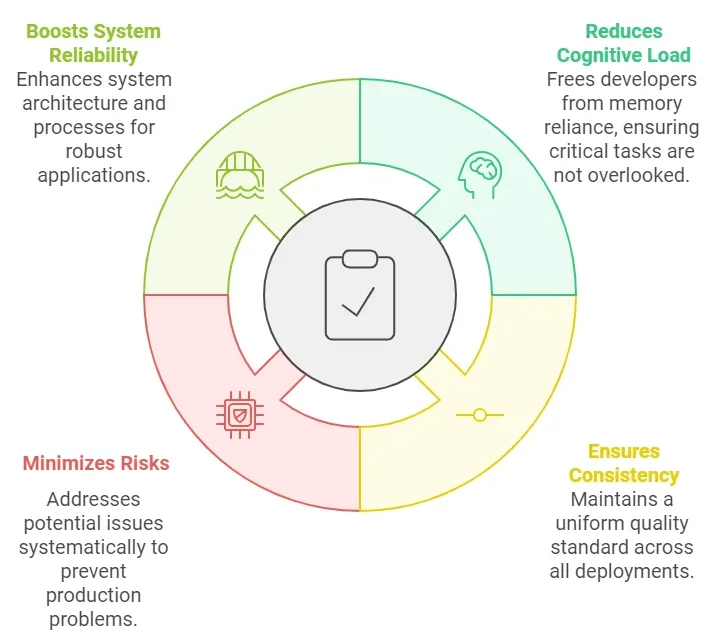
A production readiness checklist is more than just a tool; it’s a cornerstone of successful software delivery. Here’s why every development team should prioritize it:
- Reduces Cognitive Load and Ensures Consistency: A well-structured checklist eliminates dependence on memory or individual expertise while ensuring every release undergoes thorough evaluation, maintaining high-quality standards across deployments.
- Minimizes Risks and Enhances System Resilience: Systematically addressing potential issues before they arise reduces the chances of critical problems, leading to smoother releases. Over time, this process fosters continual improvements in your system’s architecture and practices, resulting in a more dependable application.
Essential Components of a Production Readiness Checklist
Security Measures
Security is critical to production readiness, as it protects your application, users, and data from vulnerabilities and threats. Here’s how to ensure robust security in your production environment.
- Robust Authentication and authorization: Implement secure user authentication using industry-standard protocols like OAuth 2.0, OpenID Connect, or JSON Web Tokens (JWT).
- Enforce role-based access control (RBAC) to limit access to sensitive features and data.
- Regular Vulnerability Assessments: Regularly scan your codebase and third-party dependencies for known vulnerabilities.
- Use tools like Synl, OWASP ZAP, or Dependency-Track to automate the detection and mitigation of risks.
- Data Encryption: Ensure that sensitive data is encrypted at rest (e.g., database encryption) and in transit (e.g., HTTPS).
- Use strong encryption algorithms like AES-256 for data at rest and TLS 1.2/1.3 for data in transit.
- Secret Management: Avoid hardcoding sensitive credentials like API keys, database passwords, or tokens in your code.
- Use secret management tools such as HashiCorp Vault, AWS Secrets Manager, or Azure Key Vault to store and manage sensitive data securely.
Example of implementing secure secret management in a Node.js application
Below is an example of how to securely fetch and manage secrets in a Node.js application using Google Cloud Secret Manager:
const { SecretManagerServiceClient } = require('@google-cloud/secret-manager');
async function getSecret(secretName) {
const client = new SecretManagerServiceClient();
const [version] = await client.accessSecretVersion({
name: `projects/your-project-id/secrets/${secretName}/versions/latest`,
});
return version.payload.data.toString('utf8');
}
// Usage Example
(async () => {
try {
const dbPassword = await getSecret('database-password');
console.log('Database Password:', dbPassword);
// Use the password securely in your application
} catch (error) {
console.error('Error accessing secret:', error);
}
})();
This approach ensures that sensitive information is never exposed in your code or version control, reducing the risk of breaches.
Performance and Scalability
Performance and scalability are critical to ensure your application remains responsive and reliable, even under varying loads or high traffic conditions. Implement the following strategies to prepare your production application:
- Load Testing: Simulate real-world traffic scenarios using tools like Apache, JMeter, Gatling, or Locust to identify performance bottlenecks.
- Analyze metrics like response time, throughput, and error rates to ensure the application can handle expected traffic loads.
- Auto-Scaling: Set up auto-scaling in your infrastructure (e.g., AWS Auto Scaling, Kubernetes Horizontal Pod Autoscaler) to dynamically allocate resources during traffic spikes.
- Ensure proper configurations to avoid over-provisioning or under-provisioning resources.
- Query Optimization: Regularly review database queries for inefficiencies such as unnecessary joins or lack of proper indexing.
- Use database profiling tools (e.g., MYSQL EXPLAIN, PostgreSQL EXPLAIN ANALYZE) to fine-tune query performance.
- Caching Strategies: Reducing load on the primary database and improving response times by caching frequently requested data. You can implement caching at various levels:
- Application level: Use in-memory caching with libraries like Redis or Memcached.
- Database level: Enable query caching features where supported.
- Content Delivery Network (CDN): Cache static assets (e.g., images, scripts) close to end-users.
Example of implementing a caching strategy using Redis in a Node.js application:
Below is an example of implementing a caching strategy using Redis to reduce database load and improve response times.
const redis = require('redis');
const client = redis.createClient();
async function getCachedData(key) {
return new Promise((resolve, reject) => {
client.get(key, async (err, data) => {
if (err) return reject(err);
if (data !== null) {
console.log('Cache hit');
resolve(JSON.parse(data));
} else {
console.log('Cache miss');
// Fetch data from the primary source
const newData = await fetchDataFromPrimarySource();
// Cache the new data with a TTL (Time-To-Live) of 1 hour
client.setex(key, 3600, JSON.stringify(newData));
resolve(newData);
}
});
});
}
// Example Usage
async function fetchData() {
const key = 'unique-data-key';
try {
const data = await getCachedData(key);
console.log('Data:', data);
} catch (error) {
console.error('Error fetching data:', error);
}
}
fetchData();
Observability and Monitoring
Observability is the cornerstone of maintaining and optimizing your application's performance and reliability in production. Effective monitoring strategies ensure you can detect and resolve issues before they impact users.
Centralized Logging: Ensure logs are structured and tagged with metadata (e.g., timestamps, request IDs) for easier filtering and troubleshooting. Aggregate logs from application components using tools like:
- ELK Stack (Elasticsearch, Logstash, Kibana): Ideal for searching, analyzing, and visualizing log data.
- Splunk: Offers powerful data analysis capabilities and enterprise-grade solutions.
Application Performance Monitoring (APM): Use APM tools like New Relic, Datadog, or AppDynamics to monitor application behavior in real-time.
- Track critical metrics such as response times, error rates, and throughput.
- Enable distributed tracing to diagnose performance issues across microservices.
Custom Dashboards: Create intuitive dashboards to visualize key performance indicators (KPIs) such as:
- System health: CPU and memory usage, disk I/O, and network traffic.
- Application metrics: Request rates, latencies, and error counts.
- Use tools like Grafana or Kibana to design and share dashboards with your team.
Alerting: set up proactive alerts for critical thresholds (e.g., high CPU usage, low disk space, or API failures).
- Use tools like PagerDuty, OpsGenie, or VictorOps to notify on-call engineers immediately.
- Implement escalation policies to ensure unresolved issues are addressed promptly.
Effective alerting is crucial for responding to critical production issues promptly. Tools like SigNoz enhance your alerting capabilities, ensuring real-time notifications and informed decision-making.
For a step-by-step guide on creating and managing alerts in SigNoz, refer to Setup Alerts Notification Channels.
Reliability and Resilience
Building reliability and resilience into your system ensures that your application can handle partial failures gracefully without significantly impacting user experience. Here are the essential strategies to implement.
- Redundancy: Eliminate single points of failure by introducing redundancy at critical layers:
- Server redundancy: Use load balancers to distribute traffic across multiple instances.
- Database redundancy: Set up primary-replica configuration or cluster solutions like MySQL Cluster or Amazon Aurora.
- Network redundancy: Implement multi-zone or multi-region deployments in cloud environments.
- Regularly test failover mechanisms to ensure they function correctly under failure conditions.
- Chaos Engineering: Conduct controlled experiments to identify weaknesses in your system under adverse.
- Use tools like Chaos Monkey (from Netflix’s Simian Army) or Gremlin to simulate outages and latency. Learn from these experiments to improve fault tolerance and system stability.
- Backup and Recovery: Automate regular backups of critical data and verify the integrity of backup files.
- Define and test your disaster recovery (DR) plan:
- Recovery Time Objective (RTO): The maximum acceptable downtime.
- Recovery Point Objective (RPO): The maximum acceptable data loss period.
- Use cloud-based backup solutions like AWS Backup or on-premise tools like Veeam.
- Define and test your disaster recovery (DR) plan:
- Graceful Degradation: Design your application to maintain core functionality even when some components fail.
- Showing cached data when the database is unavailable.
- Offering read-only functionality when write operations fail.
- Implement circuit breakers (exception handlers) to prevent cascading failures.
Example: Circuit Breaker with Opossum in Node.js
The following example demonstrates how to use the Opossum library to implement a circuit breaker pattern in Node.js:
const CircuitBreaker = require('opossum');
// Configuration options for the circuit breaker
const options = {
timeout: 3000, // Trigger failure if the function takes more than 3 seconds
errorThresholdPercentage: 50, // Trip the logic after 50% of requests fail
resetTimeout: 30000, // Wait 30 seconds before trying again
};
// Wrap the function that might fail with a circuit breaker
const breaker = new CircuitBreaker(functionThatMayFail, options);
// Provide a fallback in case the circuit is open
breaker.fallback(() => ({ error: 'Service unavailable. Please try again later.' }));
// Using the circuit breaker
breaker.fire()
.then(response => console.log('Success:', response))
.catch(error => console.error('Failure:', error));
How to Implement a Production Readiness Review Process
A well-executed production readiness review process ensures your application meets quality, performance, and security standards before deployment. Here’s a step-by-step guide to implementing an effective process:
Establish a Cross-Functional Team: Assemble a team with expertise across development, operations, security, and quality assurance.
- Assign roles for specific checklist components, such as performance testing, vulnerability assessment, or compliance verification.
- Encourage collaboration to identify potential gaps that individual teams might overlook.
Example: Developers can focus on code efficiency, while security experts review compliance and vulnerability scans.
Define Clear Acceptance Criteria: For every item in your checklist, specify measurable and actionable standards to determine whether it is a “pass” or “fail.” For Example:
- Performance: API response time must be under 200ms for 95% of requests during peak load.
- Security: All dependencies must pass a vulnerability scan with no critical or high-risk issues.
- Monitoring: Alerts for critical issues must route to the on-call team within 1 minute.
Note : Leverage templates or previous reviews to create well-defined criteria that are easy to follow.
Conduct Regular Reviews:
- Shift-left approach: Incorporate production readiness checks early and regularly in the development lifecycle to identify and fix issues incrementally.
- Schedule key reviews at the following stages:
- Pre-development: Confirm architectural designs meet production standards.
- Mid-development: Verify progress against critical readiness criteria.
- Pre-deployment: Perform a comprehensive review of the final release.
Iterate and Improve: After each review, document findings and lessons learned. You can use these insights to:
- Refine the checklist by adding or removing items based on evolving requirements.
- Improve processes by identifying bottlenecks or redundant steps.
Encourage feedback from all stakeholders to ensure the checklist remains relevant and practical. For example, If a recurring issue is identified, such as missed alert configurations, include specific steps to verify these future reviews.
Leveraging SigNoz for Enhanced Observability
SigNoz is an open-source APM tool that can significantly enhance your observability efforts. It provides:
- End-to-end Tracing: Track requests and monitor the journey of data across microservices or components in your application, identifying bottlenecks and performance issues.
- Metrics Monitoring: Collect and visualize metrics like response times, error rates, and resource utilization to ensure the system performs optimally.
- Log Management: Aggregate and analyze logs from different parts of your system to detect anomalies, troubleshoot errors, and improve debugging efficiency.
- Custom Dashboards: Create tailored dashboards to display KPIs and monitor the health of your application in real-time.
To get started with SigNoz:
- Install SigNoz using Docker:
# Clone the SigNoz repository
git clone -b main <https://github.com/SigNoz/signoz.git>
# Navigate to the deploy directory
cd signoz/deploy/
# Run the installation script to set up SigNoz
./install.sh
This deploys SigNoz and all necessary components (loke backend services, Elasticsearch, and the UI) using Docker containers. Once done, SigNoz runs on your local machine, and you can access the dashboard.
- Cloud Deployment Option: SigNoz also provides a cloud option, so you can skip the local setup and opt for a managed service to avoid infrastructure management. Here’s how to get started with SigNoz Cloud:
- Visit SigNoz Cloud and sign up for an account.
- Follow the SigNoz Cloud dashboard instructions to integrate your application with their cloud-based observability services.
This eliminates the need for manual installation and configuration, as SigNoz handles all aspects of hosting and scaling.
SigNoz cloud is the easiest way to run SigNoz. Sign up for a free account and get 30 days of unlimited access to all features.

You can also install and self-host SigNoz yourself since it is open-source. With 19,000+ GitHub stars, open-source SigNoz is loved by developers. Find the instructions to self-host SigNoz.
By integrating SigNoz into your production environment, you can gain deeper insights into system behavior, enhance proactive monitoring, and respond swiftly to issues, improving reliability and performance.
Best Practices for Maintaining Production Readiness
Maintaining production readiness is an ongoing process that requires proactive measures and a culture of continuous improvement. Follow these best practices to ensure your applications stay prepared for production environments.
Automate checklist validation: Integrate automated validations into your CI/CD pipelines to streamline the readiness process and reduce human error. This ensures consistency, speeds up deployments, and allows teams to focus on higher-value tasks.
- Automate tasks such as:
- Running security scans (e.g., Synk, OWASP Zap).
- Performing performance tests (e.g., JMeter, Locust).
- Verifying compliance with Infrastructure as Code (IaC) configurations.
Example: Use tools like Jenkins or GitHub Actions to trigger checklist validations as part of the build or deployment pipeline.
- Automate tasks such as:
Keep the checklist updated: Regularly revisit your checklist to reflect changes in:
- Technology: Adopt new tools or frameworks that enhance security, performance, or scalability.
- Threat landscape: Address emerging vulnerabilities or compliance requirements.
- Organizational goals: Align the checklist with evolving business objectives.
Note: Schedule periodic reviews (e.g., quarterly) to update the checklist with lessons learned from previous deployments or industry advancements.
Foster a culture of shared responsibility: A culture of shared responsibility improves accountability and ensures everyone works toward delivering reliable and robust software.
- Make production readiness a team-wide priority rather than limiting it to the operations team.
- Encourage collaboration between developers, DevOps engineers, QA teams, and security experts.
- Provide training and resources to help all team members understand and contribute to readiness efforts.
Example: Incorporate production readiness discussions into sprint planning and retrospective meetings.
Conduct post-mortem analyses: Conduct a blameless post-mortem to analyze the root cause after any production incident or downtime. Use these insights from the analysis to:
- Add new items to the checklist if gaps are identified.
- Improve existing processes to prevent similar incidents in the future.
- Enhance team learning and resilience.
Note: Document findings in a shared repository for future reference and continuous improvement.
Key Takeaways
- A comprehensive production readiness checklist is essential for secure, reliable, and performant software deployments.
- Key areas to focus on include security, performance, observability, and reliability.
- Regular reviews and continuous improvement are crucial for maintaining readiness.
- Tools like SigNoz can significantly enhance your observability and monitoring capabilities.
FAQs
What is the difference between a staging environment and production readiness?
| Aspect | Staging Environment | Production Readiness |
|---|---|---|
| Definition | A simulated environment that mimics production for final testing before deployment. | A comprehensive state of preparedness, encompassing processes, checks and validations beyond environment setup. |
| Focus | Validating functionality, performance, and integration under conditions similar to production. | Ensuring the application meets all security, reliability, scalability, and operational requirement. |
| Scope | Focused on testing the application in a production like environment. | Covers infrastructure, processes, monitoring, and team readiness. |
| Frequency | Used for every release or major change before production deployment. | Conducted periodically or integrated into the development lifecycle for continuous improvement. |
| Outcome | Identifies issues in application behavior that might occur in production. | Certifies the application and associated systems as fully prepared for live environments. |
How often should production readiness reviews be conducted?
Ideally, production readiness reviews should be conducted regularly throughout the development cycle. For example:
- Sprint or iteration-based reviews in agile environments.
- Pre-release reviews to ensure that everything is aligned before a major release.
The frequency may vary based on your release cadence, but it is important to have a final review before each major release and to monitor for improvements as the application evolves continuously.
Can production readiness checklists be automated?
Yes, many aspects of a production readiness checklist can be automated using CI/CD pipelines, automated testing tools, and monitoring systems. Automation can handle tasks like:
- Security scans (e.g., vulnerability scanning).
- Performance testing (e.g., load testing).
- Infrastructure as code validations.
However, sometimes, such as business logic validation or certain compliance checks may still require manual review or decision-making.
How does production readiness impact DevOps practices?
Production readiness plays a crucial role in DevOps practices by aligning development, operations, and security teams. It promotes:
- Collaboration between teams to ensure all aspects of the application are ready for deployment.
- Automation of checks, deployments, and monitoring to ensure consistent quality.
- Continuous improvement by allowing teams to learn from past incidents and reviews.
Production readiness ensures that the development and operations teams share an understanding of what constitutes a production-ready application, making deployments smoother and more reliable.
